The Most Adaptable Parallel File System
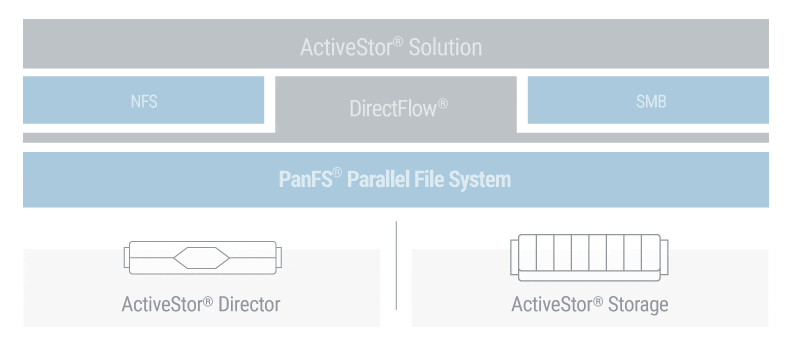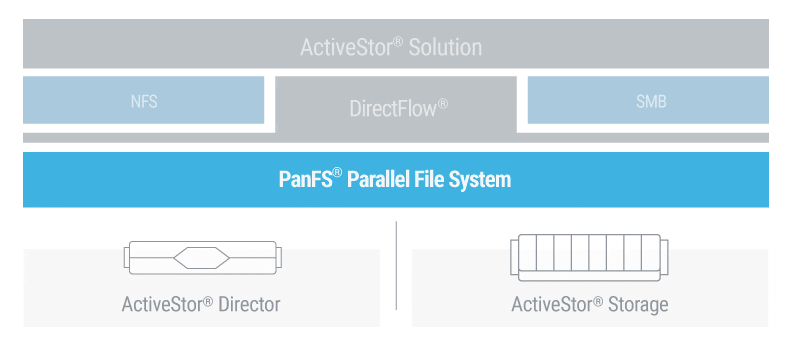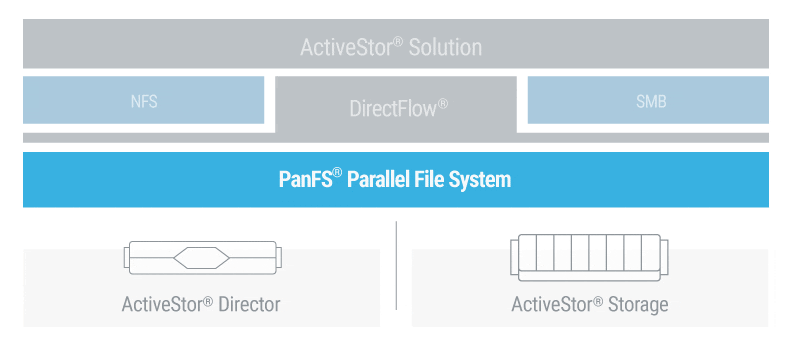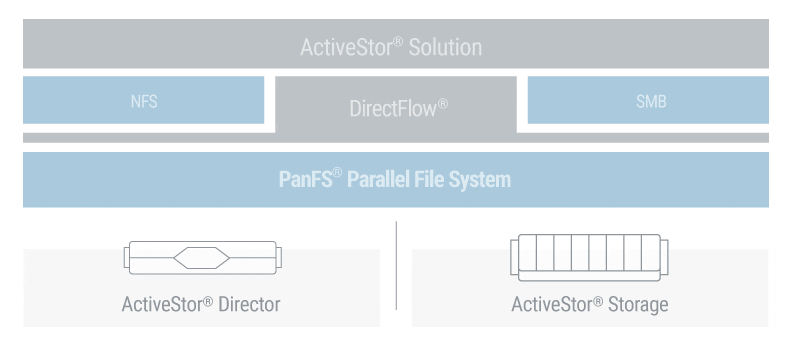
Panasas® PanFS®, the operating environment for the Panasas ActiveStor® architecture, maximizes the efficiency of all storage media in a seamless, total-performance storage system. PanFS uses Dynamic Data Acceleration to automatically adapt to changing file sizes and workloads, delivering consistently superior performance for today’s demanding workloads. A scale-out object back-end supports limitless scaling, while optimal data placement and an internally balanced architecture boost efficiency. All with frustration-free deployment, operation, and maintenance.
For more information on the PanFS operating environment, download the Panasas Architectural Overview white paper.








