Estimated reading time: 5 minutes
When it comes to describing the latest technologies, we often toss around the phrase “state of the art” without being aware that we’re actually referring to a constantly moving target.
For example, consider the example of high-performance computing (HPC) storage solutions, which help researchers keep pace with the massive volumes of information that need processing. Increasingly, HPC plays a central role tackling some of the most complicated problems around, from gene sequencing to vaccine development to computational fluid dynamics. Indeed, the worldwide market for HPC storage is growing at 7 percent CAGR and expected to reach $7 billion by 2023, according to a study by Hyperion Research that was commissioned by Panasas.
But describing an HPC system as being state of the art doesn’t really account for the entire calculus of considerations that labs, universities and other customers planning large-scale storage infrastructures must factor into their buying decisions. Not only are they expensive to buy, maintain, and operate but the costs of downtime and outages often get overlooked until it’s too late.
Users are waking up to that realization. While 57 percent of HPC storage buyers surveyed by Hyperion cited performance as the top criterion in their decision, 37 percent mentioned long-term value, or total cost of ownership (TCO) as a key factor.
Familiar Headaches
HPC storage was historically focused on managing “big” files, whether a massive climate simulation or streaming massive files needed to create or serve up a CGI movie. Hardware and file systems were optimized for these scenarios. Many platforms relied on file systems that were ostensibly open source. Often platforms required more tuning after completing a job, or in preparation for a different job.
But in the commercial world, there’s no tolerance for downtime and the kind of staff investment required to keep things running. These systems are expected to show a return on investment and handle multiple workloads simultaneously. In recent years, small files have played an increasing role, partly due to the demands of AI workloads, though anecdotally a similar pattern is being seen in traditional HPC areas such as life sciences and computational fluid dynamics.
Parallel file systems – with all the components talking to each other – were in danger of being swamped as the ratio of comms overhead to processing overhead increased.
The use of flash helped address the problem, but their deployment remains extremely expensive compared to traditional hard drives. One solution is to integrate flash and traditional storage into the same platform. But that raises the challenge of managing the various tiers, to ensure they are used in the most performant way possible.
The Cost of Complexity
The Hyperion results highlighted several revealing insights about TCO as it applies to the field of HPC.
One major cost is people. 43 percent of installations requiring one to three people to maintain it, while eight percent needed four to five. Five or more specialists were required at 10 percent of HPC storage installations. So, although just over a quarter of installations spent $100,000 or less in staffing, almost a third saw costs of $100,000 to $300,000, and almost 14 percent cost over $500,000. Simply recruiting and training storage experts was the most challenging operational aspect of HPC storage for 38 percent of organizations.
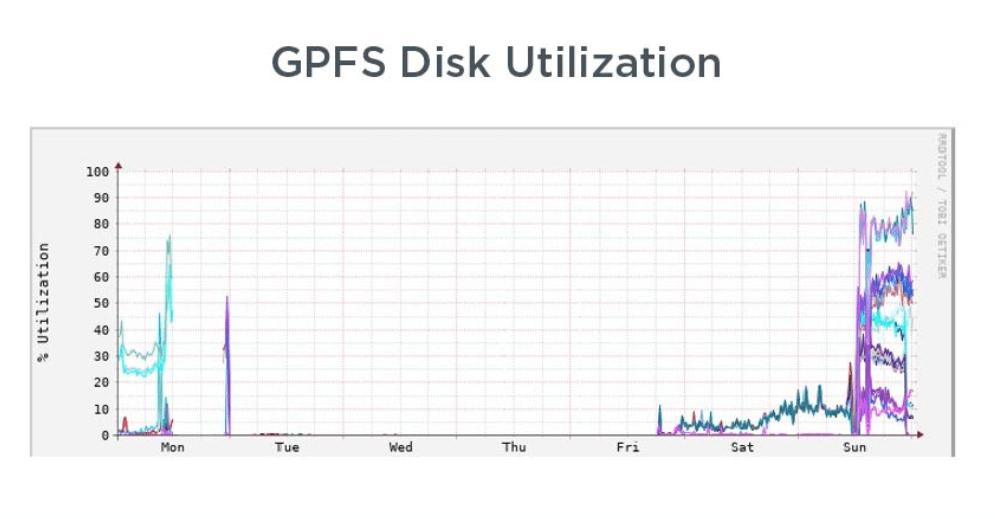
Installation is also a major challenge. Just six percent of organizations had their new HPC storage rigs up and running within a day, with 38 percent needing two to three days. Over a quarter needed four to five days, with a similar number still unboxing after a week. Storage systems being down is a major headache even when they are – theoretically – up and running. Almost half of respondents said they had to tune and retune systems monthly, with 4 percent retuning weekly and two percent daily. Storage failures are similarly ubiquitous, with one third of organizations experiencing monthly failures and eight percent experiencing weekly outages.
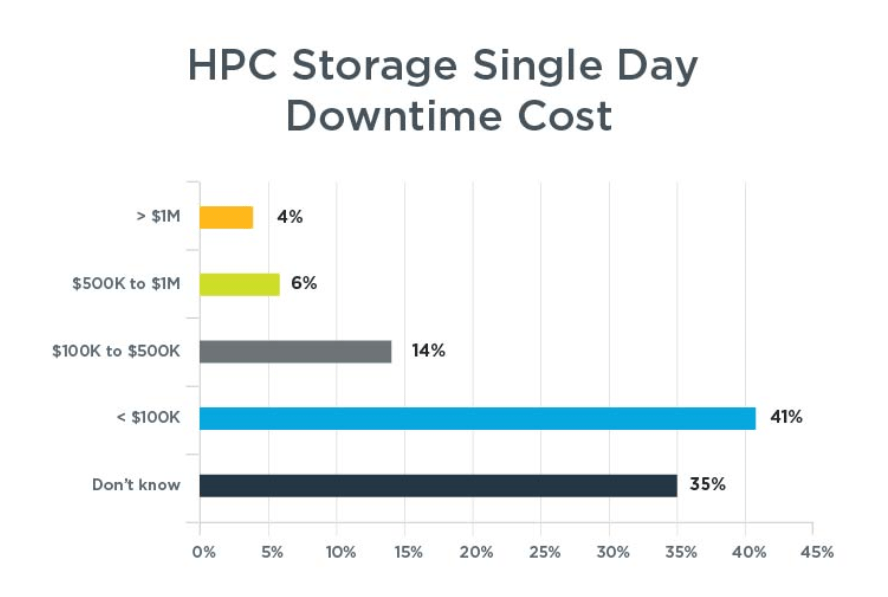
While 59 percent said recovery usually took a day or less, 24 percent took two to three days, while 14 percent took up to a week and three percent took more than a week. This is expensive, particularly for commercial customers adopting HPC storage, with 41 percent of organizations costing a day’s outage at up to $99,000. Fourteen percent put the cost at $100,000 to $500,000, with six percent hitting $500,000 to $1M. A shocking one million dollars was the cost of failure per day for four percent.
With HPC storage installations expected to facilitate a wider variety of jobs, involving different file types, and with organizations developing a lower tolerance for failure, buyers will inevitably pay more attention to TCO.
Performance Comparisons
Measuring the performance of HPC storage is an inexact science. There are a range of well-established parallel file systems, on a variety of hardware platforms. Each installation is built for the specific needs of the client and its chosen applications. Panasas engineers have fixed on bandwidth-per-drive as the best way to get a comparable MB/s-per-dollar metric across different systems.
The company used as its baseline a four ASU Panasas ActiveStor Ultra with PanFS and 96 HDDs, giving a read throughput of 12,465 MB/s, or 13.0 GB/s/100 HDDs. Drilling into published performance figures on IBM’s Elastic Storage Server, running GPFS, shows an HDD-based Model GL4S is rated at 24 GB/s and has 334 disk drives. This delivers a throughput of 7.2GB/s/100 HDDs.
For a comparison with Lustre, Panasas looked at published data on a system installed at a large academic site. This system delivered 7.6 GB/s/100 HDD. To gain an insight into the performance of BeeGFS, Panasas looked at figures on the BeeGFS website, and focused on a ThinkParQ authored performance white paper which pointed to a performance of 7.8 GB/s/100 HDD.
All these results were based on non-caching systems. Panasas did a similar comparison with a Lustre-based DDN EXAScaler SFA18K which delivered an impressive 15.0 GB/s/100 HDD, according to publicly available figures. It was not clear if this system utilized caching, but assuming it does, the ActiveStor Ultra’s write-through read back cached results are 25.4 GB/s/100 HDD. Panasas believes these comparisons constitute a simple way to assess the relative performance of parallel file system based high-performance storage systems using easily found public information.
But they give the company enough confidence to state that Panasas ActiveStor Ultra with PanFS delivers serious competition to rival platforms and should be shortlisted when planning new or replacing existing high-performance storage deployments.
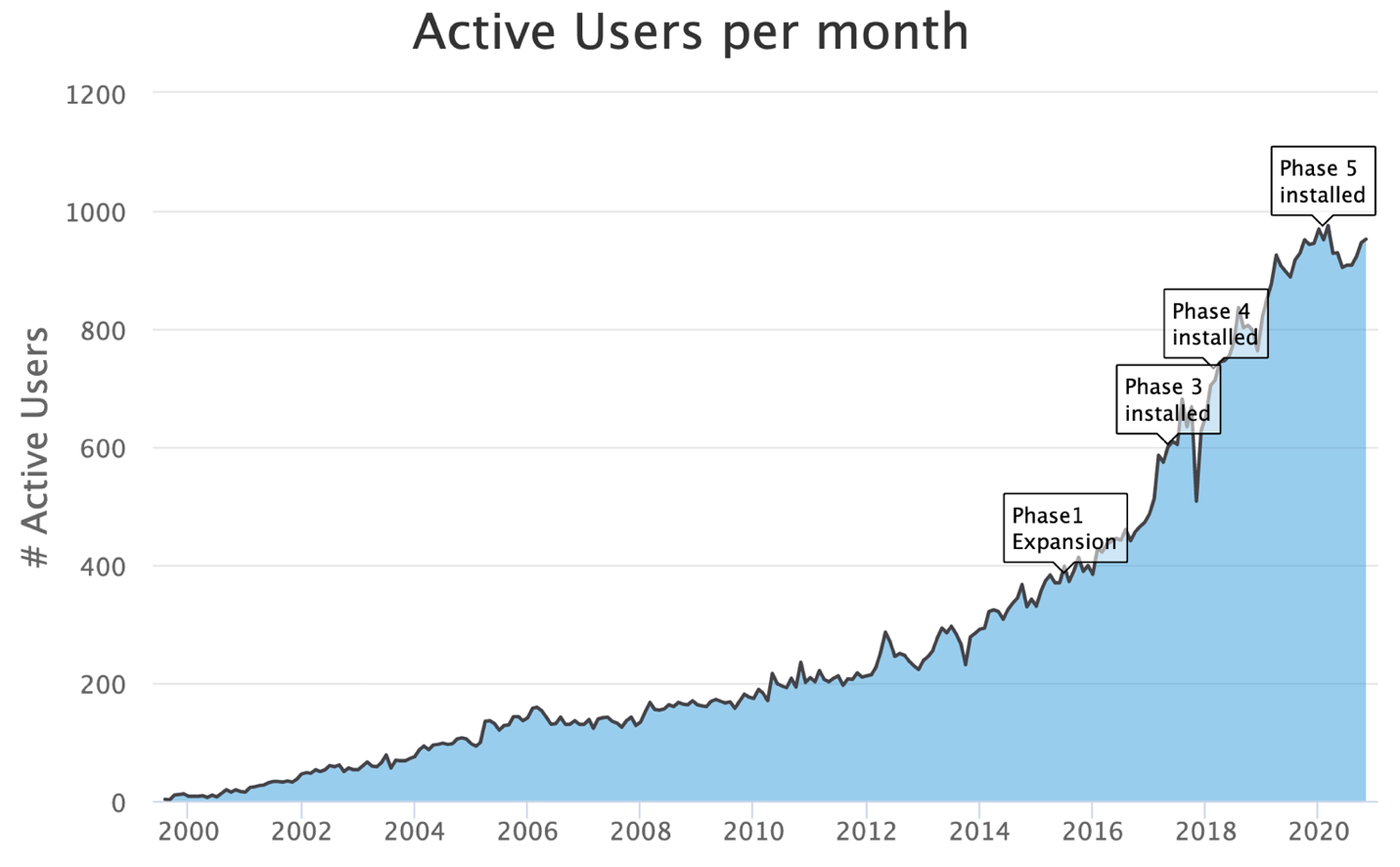
These are important considerations as HPC storage installations increasingly tackle a broader range of problems, including AI and analytics. The shortcomings of traditional approaches are becoming increasingly clear and the hidden costs of HPC storage such as staffing and outages are harder to disguise or ignore.