

Estimated reading time: 1 minute
Hyperion Research conducted a survey for Panasas to better understand the relationship between total cost of ownership (TCO) and the initial expenses involved in the acquisition of High-Performance Computing (HPC) storage systems, along with an examination of the benefits of greater simplicity in HPC storage systems. When the results came in, the findings revealed a big disconnect between HPC organizations’ storage buying criteria and the operational issues they later encounter (more on this here). What’s more, the Hyperion report was very clear about the devastating toll those operational issues have on productivity and TCO.
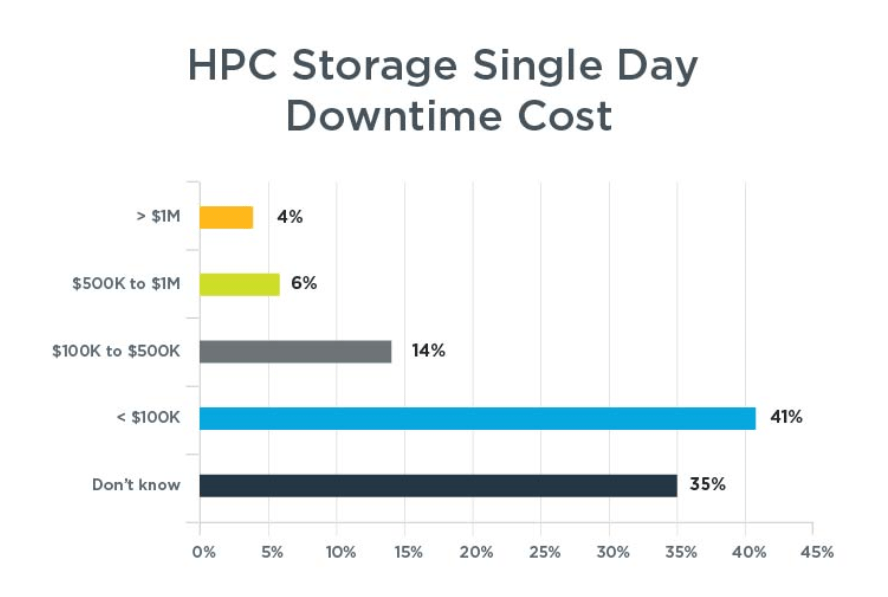
But the survey only reported each finding individually without describing the collective impact. For example, one response exposed nearly average monthly downtime for HPC storage systems, while another said that it took an average of almost 2 days to recover from that outage. And yet another found that the average daily cost of downtime was $127,000.
Linking these findings together shows how the costs compound, especially when extended over an HPC storage system’s expected 5-year lifecycle. The data in the chart below tell quite a story.
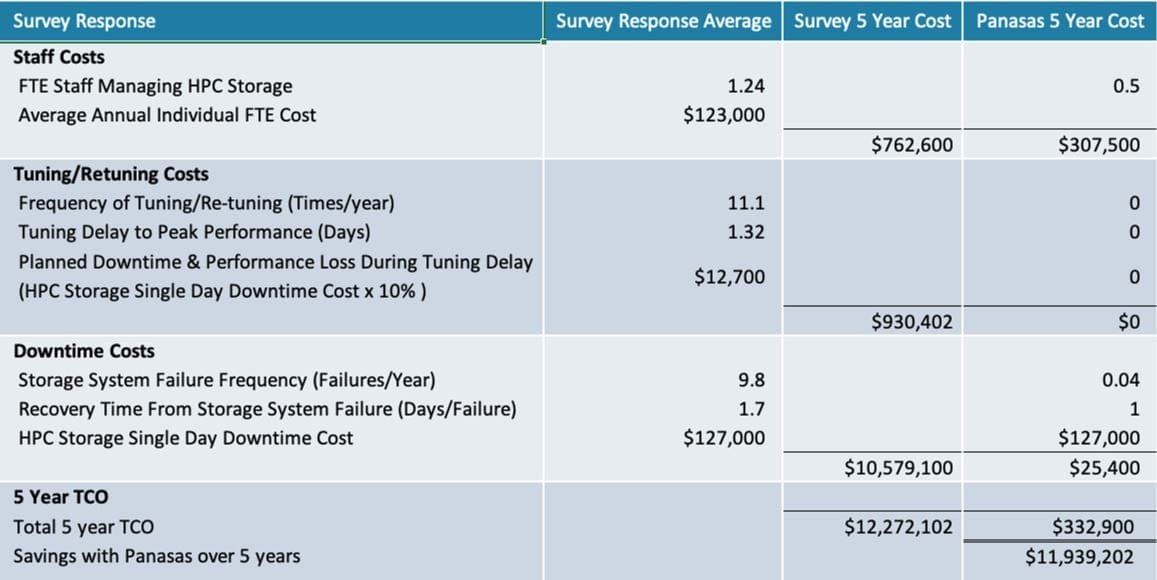
This cumulative calculation shines a light on the staggering downtimes costs suffered by the average HPC storage system. It also points to the smaller, but not insignificant staffing and tuning costs that often ensue. At the same time, the chart shows estimated savings in the millions if a Panasas solution were used for HPC storage compared to the surveyed systems. In fact, the results show that Panasas is over 35 times more cost-effective than the average HPC storage system surveyed.
It’s Urgent and Necessary to Take Action
The costs of chronic storage outages are enormous, ranging from lost research time to delayed product launches to missed deadlines. Along with all of that frustration and wasted effort, organizations also run the risk of losing coveted GPFS or Lustre administrators – always in short supply – to rival organizations. Bottom line: All HPC organizations urgently need to analyze their own operations to understand the impact HPC storage complexity and unreliability has on their operations. And they need to know that there is an alternative.
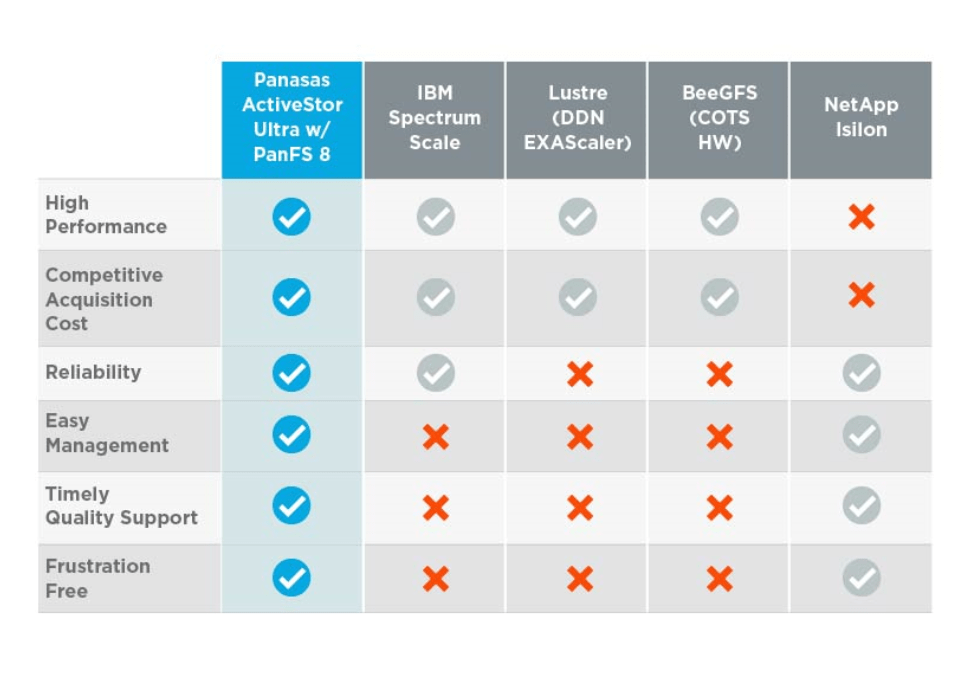
Mission-Critical HPC Storage, Performance without Risk
HPC organizations don’t need to risk their mission by depending on unreliable HPC storage. The new PanFS® parallel file system delivered on the Panasas ActiveStor® Ultra turnkey appliance provides the extreme performance, enterprise-grade reliability and manageability required to process large and complex HPC workloads and emerging applications such as AI, precision medicine, autonomous driving, and augmented and virtual reality. ActiveStor Ultra goes from dock to data in one day, providing a plug-and-play solution that is easy to install, manage and grow. With ActiveStor Ultra’s modular architecture and building-block design, customers can start small and scale linearly by scaling metadata performance, bandwidth and capacity independently and without limitations.
The re-engineered PanFS parallel file system returns Panasas to the ranks of top-performing HPC data storage systems on the market, while maintaining the frustration-free storage experience HPC organizations should expect and value. With PanFS on ActiveStor Ultra, HPC organizations can take advantage of the industry’s leading price/performance in a storage appliance that maximizes simplicity, boosts reliability, and delivers the lowest total cost of ownership.