The Shocking Costs of Complexity in HPC Storage
May 12, 2020
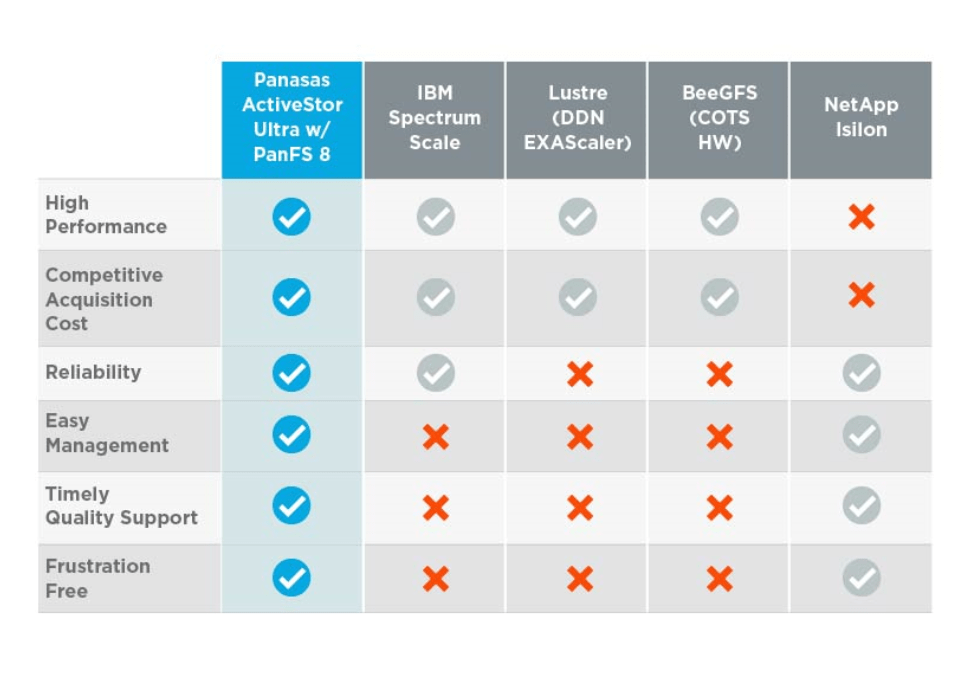
This is the next of a series of blogs about the Hyperion Research survey of HPC organizations done for Panasas to gain better insights into the relationship between total cost of ownership of High-Performance Computing (HPC) storage systems, the initial acquisition costs and the benefits users derive from greater simplicity in their installations.
Incredibly, the Hyperion report found that:
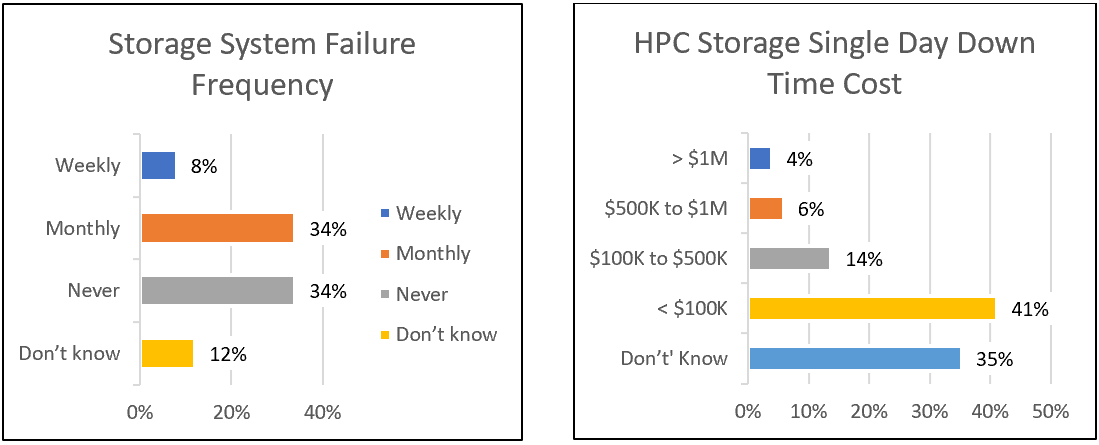
“Almost half of the surveyed sites experience storage system failures once a month or more frequently.”
– and –
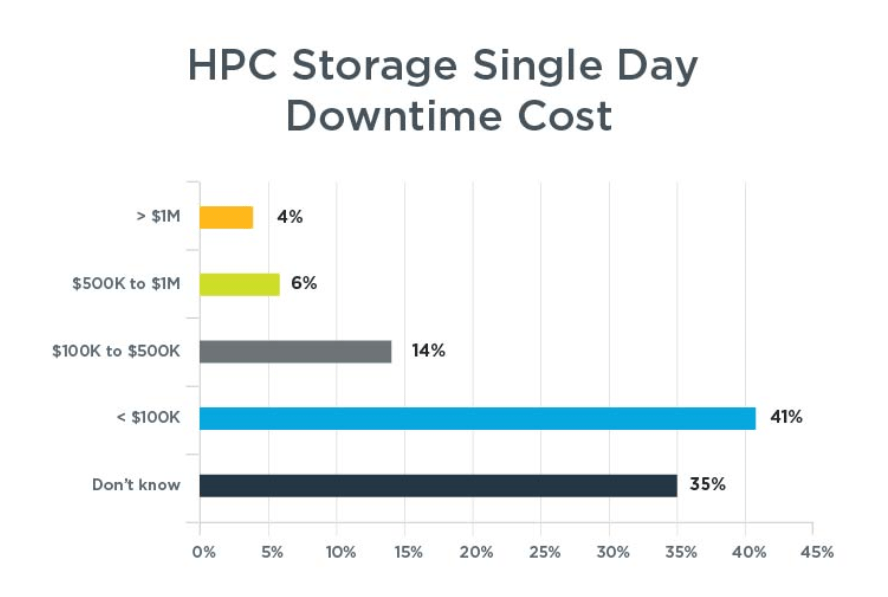
“Downtimes range from less than one day to more than a week, and a single day of downtime costs from under $100,000 to more than $1 million.”
These survey findings are shown in the charts below.
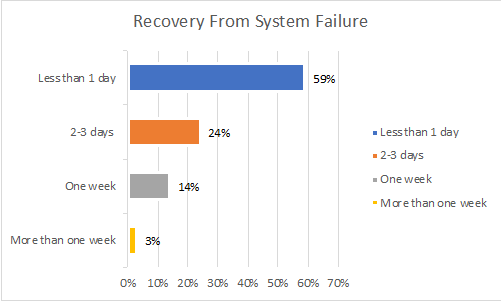
Multi-Day Recovery from HPC Storage System Failure
The reliability problem with HPC storage compounds. When asked how long it took to recover from a storage system failure, respondents said that 40% of HPC sites typically took more than two days to restore their storage system to full functionality.
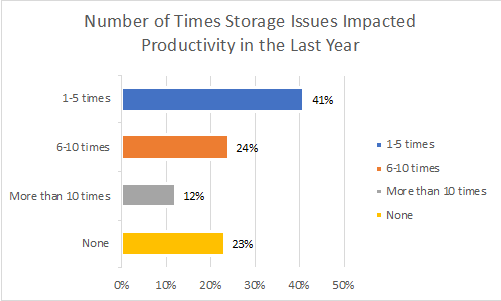
HPC Storage System Failures Cause Significant Productivity Loss
Confirming the above, the survey also asked how HPC storage system failures and recovery impacted productivity. The verdict: 78% of HPC sites reported storage-related issues over the last year that negatively impacted user productivity.
The Survey Averages Reveal an Appalling State of Affairs in HPC Storage
According to the survey, the average HPC storage system failure frequency is 9.8 failures per year. The survey average time to recover from a storage system failure is 1.7 days. And, according to the survey respondents, their average downtime cost is $127,000 per day.
This would be a completely unacceptable level of reliability for just about any contemporary IT system, let alone a storage system. In fact, when the Hyperion results were shared at a recent Panasas User Group gathering, the industry’s apparent low expectations for reliability HPC storage systems results elicited shock from the meeting presenter. The Hyperion revelations were followed by a Panasas user presentation1 that reported “Zero unplanned downtime in 8 years of operation.”
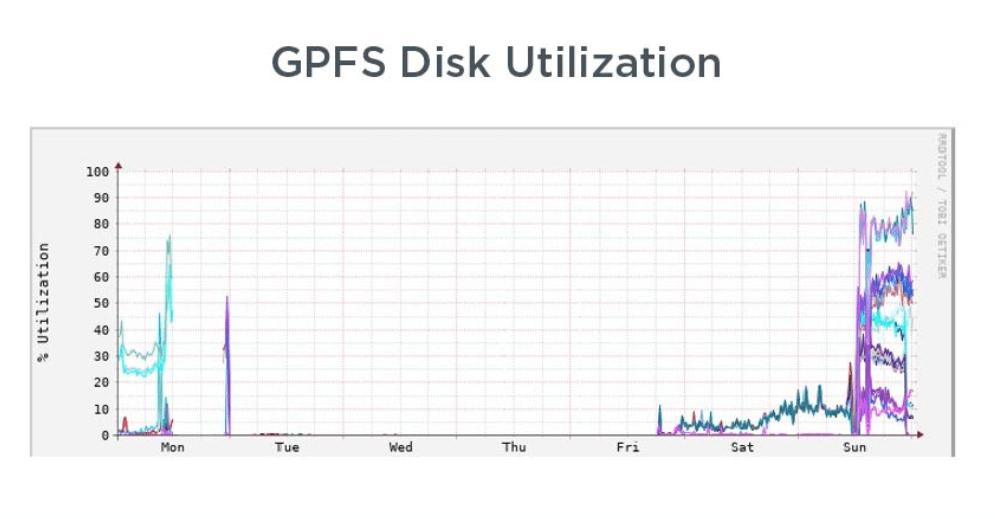
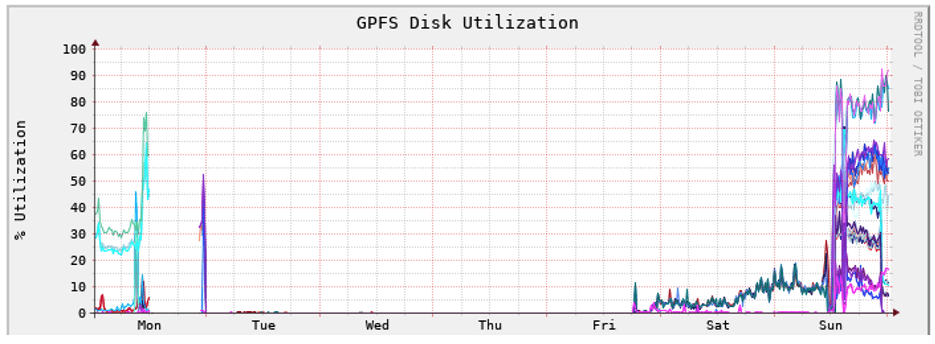
A Representative Example in the Wild
The graph below offers a vivid example of how bad things got at a prestigious American university2 which suffered frequent HPC storage outages and took several days to get their systems back up and running. Recovery experienced at this university3 is shown in the graph below with additional detail available via the link in the footnote. It shows an outage that started on a Monday and wasn’t fully recovered from until Sunday.
HPC Organization’s Seemingly Low Expectations for HPC Storage Reliability
The results of the Hyperion survey indicate it would be beneficial for most HPC organizations to expand their perception of their user’s needs beyond just performance and price, wouldn’t it?
The accepted HPC Storage “world view” that cost-effective performance can only come with complexity and unreliability has to change. We need to strive for an approach that encompasses performance with simplicity, reliability and the competent, effective support associated with cost-effective enterprise-class storage systems.
1 “Using Panasas to Reduce Complexity and TCO for HPC Workloads”
2 https://www.vanderbilt.edu/accre/category/cluster-status-notice/
3 https://www.vanderbilt.edu/accre/category/cluster-status-notice/

|
 |