
How to Choose the Right Storage for AI and HPC
June 3, 2019

At the Next AI Platform event earlier this year, I made the case that we could predict some of the future of the AI market by using the history of the HPC market, that deep learning training is best run on an HPC infrastructure, and that infrastructure can be efficiently shared with other HPC workloads. Here’s video of my interview:

Live interview at The Next AI Platform: Software Architect Curtis Anderson
I claimed that the current trend of running AI training workloads on big monolithic DGX-type GPU infrastructures, connected to dedicated, expensive flash-based storage, echoed the earliest supercomputer architectures. At that time, the software had not yet been developed that could effectively and efficiently spread a single computation across multiple computers, so “scale-out” was not yet possible. It’s now much less expensive to harness a group of simpler computers to get the same work done as a single monolithic supercomputer. Only recently have the AI “frameworks” such as TensorFlow developed that same scale-out capability. So just like what happened in supercomputing, a parallel, scale-out future is inevitable for AI.
At Panasas, we are already seeing that trend. Most of our storage systems are deployed at “shared resource” HPC centers where dozens to hundreds of projects and researchers share a large compute and storage cluster. In those centers, AI workloads are becoming an increasing part of what is hitting our storage, and our customers tell us that’s how they would like to continue to work moving forward: running AI and HPC jobs on the same infrastructure.
I was excited to see Intel AI strategist Esther Baldwin articulate a similar view in a recent insideBIGDATA article titled: “Using Converged HPC Clusters to Combine HPC, AI, and HPDA Workloads” and in the associated “HPC Converged Platform Solution Brief”. Esther’s comments and the solution brief go deeper into the efficiencies and economics of why organizations are using converged HPC clusters to combine HPC and AI workloads, and why that trend will grow. It was great validation that Intel seems to see the same future that Panasas does.
The highest-level summary of Esther’s argument can be neatly summarized in a graphic from her paper (see below). It’s clear that partitioned silos are going to have lower overall utilization of the total investment of hardware and administrative costs compared to a single shared environment. In her words, some organizations are “incorrectly adopting AI as a distinct entity, separate from traditional HPC modeling and simulation”, and “this leads to siloed clusters that suffer from underutilization and requires time consuming data transfer. Instead, it is much better to converge these clusters to run as a unified environment”. (Note that Intel also includes Analytics, which is beyond the scope of my discussion).
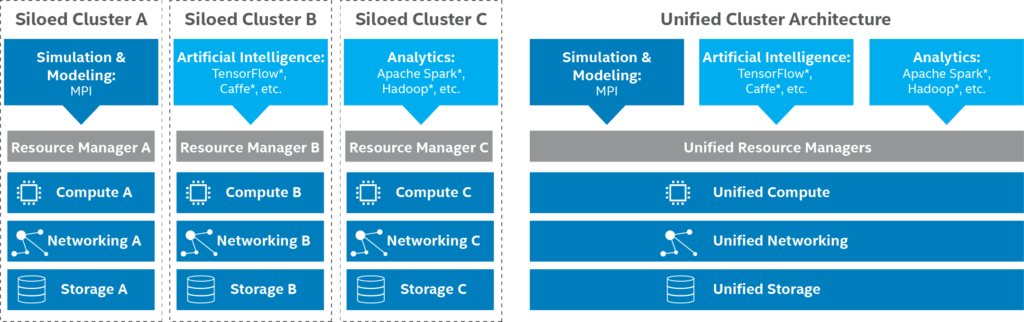
Intel’s vision of a siloed versus unified cluster architecture for HPC, AI, and Analytics workloads.
What I like about Esther’s article is the focus on how automation software like unified job scheduling and resource management can dramatically change the economics and complexity of deployment models. It used to be that smaller environments (e.g.: silos) were easier to manage because of their lower complexity. Today, the dramatically improved economics of sharing one environment across all HPC and AI needs outweighs the added complexity, and software is available to manage it for you.
The Key Hurdle to Implementing a Unified HPC AI Infrastructure Will be Storage
High throughput parallel file systems like PanFS were developed over the last 20 years specifically to meet the needs of HPC environments. On the other hand, deep learning training requires low latency random file access, which has historically been difficult for traditional HPC parallel file systems to provide. As a result, most of today’s AI deployments have been supported by very expensive all-flash storage systems. As AI deployments grow beyond the early exploratory phase, however, the amount of data required for training will quickly grow to where all-flash storage is no longer cost-effective.
So, our view, our customers’ view, and it appears Intel’s view of the future of AI aligns around a unified HPC AI infrastructure. What we all need is a high-performance storage platform than can feed these two disparate data access patterns, high bandwidth and low latency, from a single system, and does so in an economical fashion. Watch this space as it unfolds…

